[42] libasm 과제에 필요한 어셈블리어 기초 총정리
업데이트:
으악 어셈블리어라니
42 서울의 교육과정을 처음 접한 사람들은 ‘와 로우레벨부터 기초를 탄탄히 다지고 가네’라고 말하곤 한다. C언어 과제를 도대체 몇 개나 하는 거냐며, 언제까지 메모리 누수를 잡아야 하냐며 답답해하는 사람도 있다. 한창 C언어를 이용한 과제를 하다가, 이제는 어셈블리어를 익혀야 하는 과제를 만나게 되었다. 과제를 진행하다 보니, 새삼 C언어가 정말 ‘고오급’ 이구나 싶은 생각이 들었다.
libasm 과제는
이번 서클 과제 자체가 minishell 과 libasm 이 나란히 있는 걸 보면 쉘과 운영체제에 대해서, 그리고 로우레벨 언어를 한 번씩 짚고 넘어가게끔 하는 의도인 것 같다. 당연히 어셈블리어로 무슨 대단한 프로젝트를 시키지는 않지만, 어셈블리어로 C언어의 string.h 라이브러리에 내장된 함수들 중 아주 간단한 몇 개와 시스템 콜을 이용한 read, write 함수 작성을 진행하게 된다. 정확히는 아래와 같다.
- ft_strlen
- ft_strcpy
- ft_strcmp
- ft_strdup
- ft_write
- ft_read
과제 요구사항
- 64비트 어셈블리를 사용할 것.
- 인텔 문법을 사용할 것. (AT&T가 아닌 인텔을 사용해야 함)
- 어셈블리어는 CPU마다 조금씩 다르다. 이 과제에선 인텔 문법을 사용하게 되며, 인텔 문법에 최적화된 NASM 어셈블러[^1]를 사용하게 된다.
- 인라인 어셈블리를 사용해서는 안 된다.
- .s 파일을 사용해서 어셈블리 코드를 만들어줘야 하고, C언어 소스 안에 어셈블리어를 집어넣는 형태로 작성해서는 안 된다.
- 호출 규약(Calling convention)에 주의하여 코드를 작성해야 한다.
- System V AMD64 호출 규약. 해당 링크 참고
- 64비트 윈도우와 리눅스의 호출 규약 차이를 다룬 이 링크도 참고
- 함수 호출 규약을 설명한 이 링크도 참고
- 이 콜링 컨벤션에 따라 호출되는 함수는 RBX, RSI, RDI, RBP를 사용한 다음 초기값으로 돌려놓아야 한다.
어셈블리어란?
프로그래밍 언어의 일종으로, 기계어 바로 위 단계에 해당하는 언어이고, 기계어와 함께 단 둘뿐인 저급(Low Level) 언어
사람이 0101 0001 0000... 의 연속으로 이뤄지는 기계어를 읽는 것은 쉬운 일이 아니다.1 그래서 이를 보완하기 위해 기계어와 1:1 매칭이 가능하게끔 나온 것이 어셈블리어다. 어셈블리어는 기계어 한 줄당 어셈블리 명령어도 한 줄씩 대응이 되어 있고, 이걸 기계어로 변환하는 프로그램을 어셈블러라고 한다.
프로시저와 레지스터
- 프로시저 : C언어를 공부하며, 프로그램을 함수 단위로 잘게 쪼개어 작성하는 것이 얼마나 편리한지 잘 알고 있을 것이다. 해결해야 할 여러 문제들을 부분별로 나누어 풀게 된다면 코드 작성에 있어 가독성도 좋아지고 작성도 쉬워진다. 어셈블리어에선 이를 프로시저(Procedure) 이라고 부른다.
- 레지스터 : CPU가 가지고 있는 미칠듯이 빠른 저장 공간, 모든 프로세서는 한 개 이상의 레지스터를 가지고 있다. 각각의 레지스터의 공간은 CPU마다 다른데, 대부분의 경우 32비트 혹은 64비트이며(사실 2020년 기준 대부분 64비트일 것이다), 이 크기에 따라 우리가 흔히 부르는 32비트 컴퓨터냐 64비트 컴퓨터냐가 나뉜다. 레지스터에 대한 자세한 내용은 아래에…
- 엄연히 다른 개념이지만 대충 프로시저는 함수 같은 것, 레지스터는 변수 같은 것 이라고 생각하면 이해가 좀 편하다. 그런 비슷한 느낌이라는거지 절대 같은 건 아니다.
레지스터의 종류
범용 레지스터
먼저 범용 레지스터는 네 가지가 있다. X 앞에 A, B, C, D가 붙어 AX, BX, CX, DX가 있다고 외우면 편한데, A, B, C, D의 의미는 각각 다음과 같다.
- Accumulator - AX, 산술 및 논리 연산 수행
- 함수의 Return 값이 저장되는 레지스터이다.
- 시스템 콜을 사용하려면 RAX에 함수의 syscall 번호를 넣어주면 된다.
- Base - BX, 메모리 주소를 저장하기 위한 용도로 사용
- Count - CX, 반복문 등에서 카운터로 사용되는 레지스터. C언어에서 i++; 할 때 그 i와 비슷하다.
- Data - DX, 큰 수의 곱셈 혹은 나눗셈 등의 연산이 이뤄질 때 사용한다.
포인터 레지스터 및 인덱스 레지스터
포인터 레지스터와 인덱스 레지스터는 모두 범용 레지스터에 속하긴 하는데, 주로 데이터가 저장되어 있는 메모리 주소를 가리키는 포인터로써 사용된다.
- SP : Stack Pointer - 스택 내 가장 최근 데이터 주소를 가리킨다.
- BP : Base Pointer - 스택포인터 대신 스택 내의 데이터를 액세스할 때 사용한다.
- SI : Source Index - 문자열 처리 시 시작 주소 지정에 사용한다. 데이터를 복사할 때, 복사할 Source 데이터의 주소가 저장된다고 생각하면 된다.
- DI : Destination Index - 문자열 처리 시 목적지 주소 지정에 사용한다. 데이터를 복사할 때, 복사된 Destination 데이터의 주소가 저장된다.
- RSP와 RBP를 활용하기 위해 알아야 하는 스택포인터에 대한 정보2
여기까지 다룬 레지스터들은 어떤 프로세서를 사용하냐에 따라 앞에 E 혹은 R을 붙여 사용하게 된다. 예를 들어 32비트 컴퓨터용 프로그램을 만든다면 EAX, EBP 등을 사용하게 되고, 64비트 프로그램을 만든다면 R을 붙여 RAX, RBP 등을 사용하게 된다. 그냥 AX, BP로 쓰면 16비트용으로 취급한다. 간혹 인터넷에서 RAX와 EBP를 섞어서 쓴 코드를 봤는데, 혼용이 가능하다고 해서 고개를 갸우뚱했고 아직도 그 이유는 잘 모르겠다.
플래그 레지스터
조건문 처리를 할 때 비교를 하는 용도 등에 있어 플래그용으로 사용되는 레지스터다.
상태 플래그
- CF (Carry Flag) : 부호 없는 수 끼리 연산 결과가 자리올림/자리내림이 발생할 때 1, unsigned int 값을 벗어날 때 1
- OF (Overflow Flag) : 부호 있는 수 끼리 연산 결과가 용량을 초과하였을 경우 1
- SF (Sign Flag) : 연산 결과 최상위 비트가 1인 경우(연산 결과가 음수인 경우) 1
- ZF (Zero Flag) : 연산 결과가 0이면 1
- AF (Auximiliary-carry Flag) : 16비트 연산 시(10진수 연산 시) 자리올림/자리내림이 발생할 때 1
- PF (Parity Flag) : 연산 결과에서 1이 짝수개면 1, 홀수면 0
제어 플래그
- DF( Direction Flag) : 문자열 처리 시 사용하며, 0이면 전진하며 처리, 1이면 후진하며 처리
- IF (Interrupt Flag) : 인터럽트 처리 시 사용, 0이면 외부에서 들어오는 인터럽트 무시, 1이면 허용
- TF (Trap Flag) : 프로세서 처리할 때 사용하며, 기본값이 0이며 1인 경우 명령 실행 후 특정 프로시저 호출
기타 레지스터
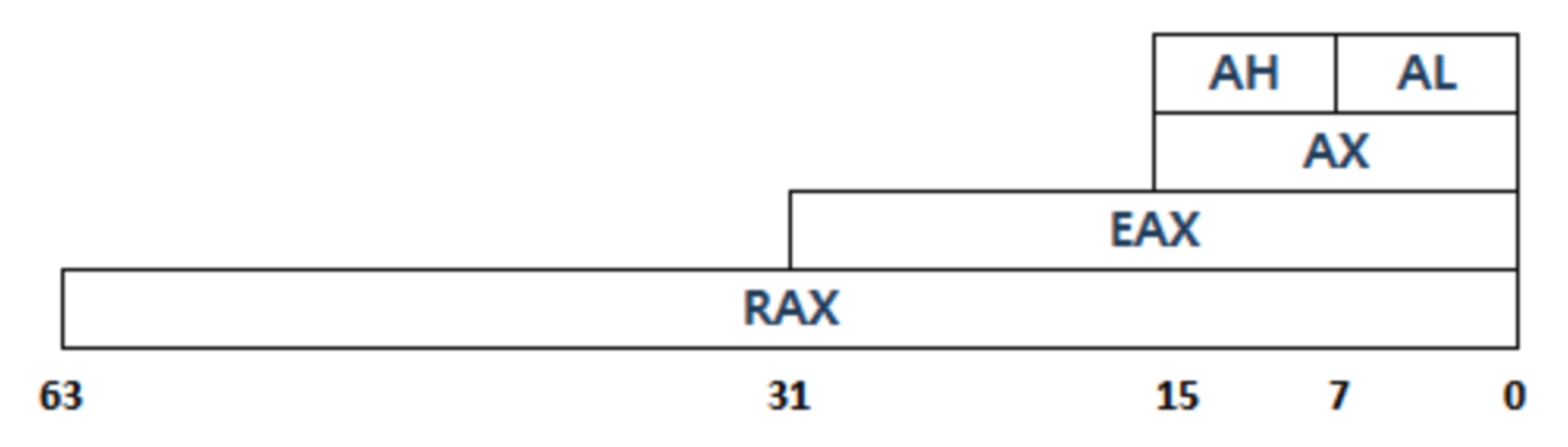
64비트에서는 R8 ~ R15까지의 8개 레지스터를 추가로 사용할 수 있고, 각각의 레지스터는 아래 그림처럼 쪼개어 사용할 수 있다. 이미지 출처
OPCODE (명령어)
opcode는 어셈블리어에서의 명령어다. 이게 총 200여가지가 된다고 하는데, 그 중에 이번 과제에 사용되는 명령어 위주로만 정리했다.
-
mov : 두 번째 인자 값을 인자 1에 넣는다. (대입, 전달한다)
MOV a b: C언어에서a = b;와 같음
-
cmp : 두 개의 오퍼랜드를 비교한다. 비교의 결과는 위에서 다룬 플래그 레지스터에 담긴다. cmp 연산 결과와 플래그에 담기는 내용은 아래와 같다.
연산 결과 ZF CF dst > src 0 1 dst < src 0 0 dst == src 1 0 - jmp : 특정 위치로 건너뛰어 코드를 실행한다. C언어의 goto 문이랑 비슷하다.
- 조건부 점프 명령어
- je : Jump if equal
- jne : Jump if NOT equal
- ja : A가 더 크면 jmp
- jb : B가 더 크면 jmp
- jae : A >= B
- be : A <= B
- 조건부 점프 명령어
- call : 특정 함수 혹은 프로시저를 호출한다. 현재 위치를 스택에 push하고 프로시저로 넘어간다는 점에서 jmp랑은 다르다고 한다. call한 위치에서 ret를 실행하면 마치 함수를 종료하듯 아까 push한 위치로 돌아가서 이어서 프로그램이 실행된다.
- push : 현재 오퍼랜드의 내용을 스택에 집어넣는다.
- pop : 스택에 넣은 값을 뽑아낸다. 예를 들어
POP RAX라면, 스택 맨 위 값(RSP가 가리키는 값)을 뽑아다가 RAX에 집어넣는다. - ret : 현재 프로시저 종료 후 원 위치로 복귀 (다음줄부터 실행)
- nop : 아무것도 하지 않음(왜 있는거지…)
- inc : 오퍼랜드의 값을 1 증가한다.
- dec : 위와 반대로 1 감소한다.
-
add : 두 번째 인자 값을 첫 번째 인자에 더한다.
ADD a b는 C언어의a = a + b같은 느낌
- sub : 두 번째 인자의 값을 첫 번째 인자에서 뺀다.
어셈블리어에서 syscall 사용하기
syscall 번호를 참고하여 사용해야 한다. macOS의 경우 /usr/include/sys/syscall.h 파일에 시스템 콜의 번호들이 나열되어 있다. 예를 들어 read 함수의 syscall 번호는 3번인데, 실제로 사용할 때는 0x2000003 으로 사용하면 된다. 앞에 2가 왜 들어가는지 의아할 텐데, macOS의 경우 syscall 번호를 여러 개의 클래스로 나누어 두었다고 한다. write나 read 등은 unix 클래스로 분류하여 최상단 비트를 2로 설정해 두었기에 저런 식으로 호출하게 된다고 한다. syscall 명령을 사용할 땐 커널이 rcx와 r11의 값을 변경시킬 수 있으니 유의해야 한다.
error 함수를 이용해 에러 처리하기
만약 syscall 사용 시 에러가 발생했다면, 이는 ___error 함수를 이용하여 처리해야 한다. syscall들은 오류가 있는 경우 rax에 음수로 errno를 반환하며 동시에 CF(Carry Flag)을 True로 바꾼다. 따라서 jc (캐리플래그가 1일 때 점프)를 이용하면 에러 처리 분기가 가능하다. 자세한 내용 보기
fd가 잘못된 write(-3, “abcd”, 4)를 사용하면 리턴값은 -1, errno는 9가 저장이 된다. errno 9번은 “Bad file descriptor”이다. (man 2 errno 문서)
여기까지 어느정도 숙지하였다면 이제 과제를 할 준비가 된 셈이다.
어셈블리어의 구문
먼저 Hello world를 살펴보자. 위의 설명과 비교하며 찾아보자면 이것들이 대충 무얼 하는 코드구나, 하고 감이 올 것이다.
section .text
global _main ;
_main :
mov rax, 0x2000004 ; write 함수 syscall 번호
mov rdi, 1
mov rsi, msg
mov rdx, 12
syscall
mov rax, 0x2000001 ; exit
mov rdi, 0
syscall
section .data
msg db "Hello World"
컴파일 및 실행은 아래와 같이 한다.
$ nasm -f macho64 hello.s
$ gcc -o hello hello.o
$ ./hello
어셈블리어의 기본 문법
어셈블리어는 정해진 표준 문법은 없고, CPU 종류에 따라 여러 가지 문법이 존재한다. 이 과제에서는 Intel x64 문법을 사용하며, 아래와 같은 기본적인 형태를 가지고 있다.
opcode operand1, operand2 ; 주석
- opcode는 위에서 살펴보았듯 명령어이고, operand는 인자의 값이다.
- 인텔 문법에서는 두 번째 오퍼랜드(operand2)가 src이고, 첫 번째 오퍼랜드(operand1)가 dest 인자다.
- 특정 레지스터의 메모리 주소를 참조할 때 대괄호를 사용하며, 여기엔 오프셋 기능이 있다 : 예를 들어 RAX 레지스터에서 +10 만큼 떨어진 메모리 주소를 표기할 때는 [RAX + 4] 와 같이 표현한다.
- C++에서 // 뒤 내용이 주석이듯, 어셈블리어는 ; 이후 내용이 주석이다.
섹션
어셈블리어 프로그램은 섹션으로 분류되어 있다. 기본적으로 data와 text 섹션으로 나뉘며, section.bbs를 사용하는 경우도 있다. 이는 컴퓨터의 메모리 구조에서 기인하는데, 이는 다음과 같다.
| stack(지역 변수) |
|---|
| heap(동적 할당) |
| BBS(unintialized) |
| Data(initialized) |
| Text(코드) |
- section.data
- 상수 혹은 스태틱 변수를 선언하는 곳
- 버퍼사이즈, 상수, 파일이름 등을 선언하는데도 사용된다.
- section.text
- 실행할 코드를 작성하는 섹션
- section.bbs
- 추가적으로 변수를 선언하는 데 사용하는 공간
어셈블리어에서의 스택 활용(스택프레임)
반드시 필요한 개념으로 이를 꼭 잘 숙지해 두어야 한다. 훌륭한 글과 영상이 많아 이들 링크로 대체…
어셈블리어의 Data type(자료형)
- BYTE : 부호 없는 1바이트, char과 동일
- WORD : 부호 없는 2바이트, short
- DWORD : 부호 없는 4바이트, int
- QWORD : 부호 없는 8바이트, double
과제의 각 함수 구현하기
- 예를 들어, 가장 간단한 함수인 ft_strlen 함수는 아래와 같이 작성할 수 있다. 처음 작성했던 소스고 어셈블리어의 이해를 위해 주석을 상세하게 달았었다.
; ft_strlen.s
section .text ; 여기서부터 실제 코드를 위한 섹션임을 알림. (section.data는 상수나 초기값을 위한 섹션, bbs도 있다)
global _ft_strlen ; ft_strlen 함수 심볼을 외부에서도 사용 가능하게
_ft_strlen:
mov rax, 0 ; rax = 0;
jmp step ; 없어도 되긴 하는데 프로시저간 이동에 있어 가독성을 위해
step:
cmp byte [rdi + rax], 0 ; 바이트 단위로 메모리를 직접 비교한다. null인지, 같으면 ZF(Zero Flag)가 1로 정해지고 아니면 0이 된다.
je done ; ZF가 1 이면 done으로 / Jump if equal, 비슷한걸로 ja, jb
inc rax ; 1이 아니면 rax 1 증가 (inc 는 ++ 같은 의미)
jmp step ; 스스로를 다시 호출
done:
ret ; rax 값을 리턴
; 개별 컴파일 방법
; $ nasm -f macho64 hello.s
; $ gcc -o hello hello.o
; $ ./hello
그 외 기타 팁들
C언어 소스를 어셈블리어로 변환하여 보기
$ gcc -S -fno-stack-protector -mpreferred-stack-boundary=4 -z exectack -o name.a name.c
출처 : yechoi님 블로그
malloc & free
malloc하기
extern malloc
mov rdi, 8
call malloc
rdi에 할당할 바이트 수를 입력하고 malloc을 call한다.
mov QWORD[rax], 3
malloc은 rax로 포인터를 반환하므로, 해당 포인터를 통해 원하는 값을 넣는다.
free하기
해제할 포인터를 rdi에 넣고, free를 call한다.
extern free
mov rdi, rax
call free
링크로 대체한 내용이 너무 많아서, 내용은 점차 추가할 예정입니다.
참고 자료
- 어셈블리를 잘 설명한 유튜브
- 시스템 콜 테이블(macOS)
- 스택프레임 설명 1
- 스택프레임 설명 2
- 42Wiki의 과제 정리
- secho님의 과제 정리
- x64 Stack의 개요(은근히 중요한 내용이 많으니 한번 살펴보세요)
- 배은태 교수님(으로 추정)의 어셈블리 강좌(대학 교과목 강의 한학기꺼 통째로)
- sancho 님의 과제 정리
- yechoi님의 “한큐에 정리하는 어셈블리 기초”
- daelee님의 “[libasm] 어셈블리 프로그램 구조와 x64 레지스터 이해하기”
- [libasm] strlen 함수를 어셈블리어로 짠다면?
- Memory Allocation in Assembly
- https://github.com/gurugio/book_assembly_8086_ko/blob/master/README.md
- https://aistories.tistory.com/12
댓글을 남겨주세요